理解MapReduce原理_mr
本文共 960 字,大约阅读时间需要 3 分钟。
用自己的话概况一下
MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。(这句话记住了是可以用来装逼的)
基本概念–job和task
作业job是客户端要求执行的一个工作单元
– 输入数据、MapReduce程序、配置信息 • 任务task是MapReduce将作业拆成的小单元 – map任务和reduce任务 • Job Tracker节点(master) – 调度task在Task Tracker上运行,协调所有作业运行 – 如果一个task失败,Job Tracker指定一个Task Tracker重新开始 • Task Tracker节点(worker) – 执行任务,发送进度报告分片的定义
– MapReduce把输入的数据划分成等长的小数据块,称为输入分片input split,简称分片• 分片大小
– 分片越小,负载越平衡 – 异构时根据计算机性能分配任务个数 – 失败重启更加平衡 – 分片越小,框架开销越大– 每个分片一个map任务
– 管理分配的总时间和构建map任务时间变大 – 默认HDFS块大小,128MB• 计算数据本地化
– 在本地存有HDFS数据的节点上运行map任务 图解:
图解: 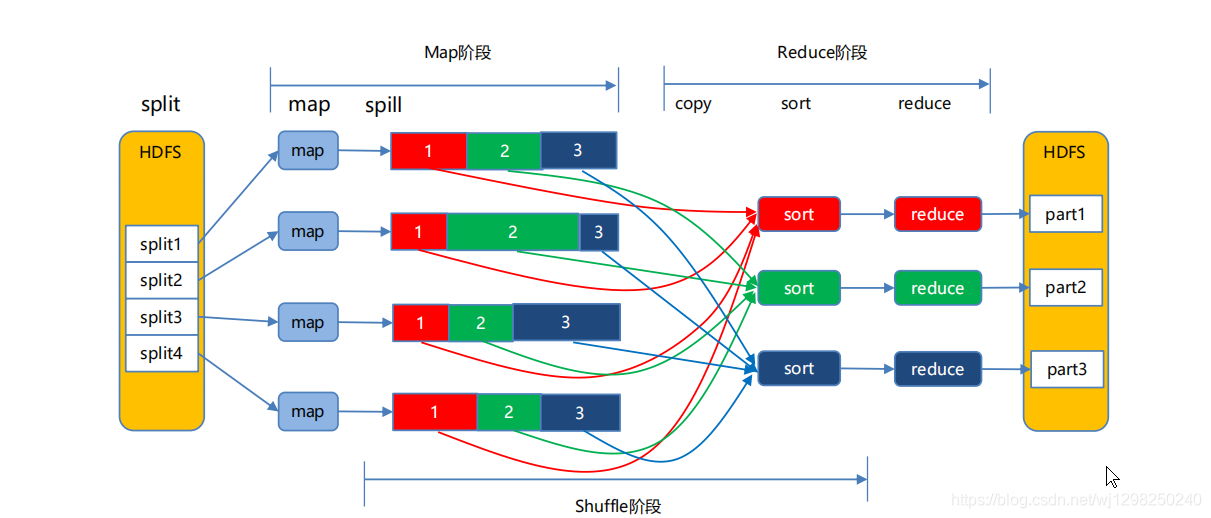
MapReduce详细过程
• 一个split(切片)起一个map任务
• map输出时会先将输出中间结果写入到buffer中 • 在buffer中对数据进行partition(分区,partition数为reduce数)和基于key的sort(排序),达到阈 值后spill到本地磁盘 • 在map任务结束之前,会对输出的多个文件进行merge(合并),合并成一个文件 • 每个reduce任务会从多个map输出中拷贝自己的partition • reduce也会将数据先放到buffer中,达到阈值会写到磁盘 • 当数据该reduce的map输出全部拷贝完成,合并多个文件成一个文件,并保持基于key的有序 • 最后,执行reduce阶段,运行我们实现的reduce中化简逻辑,最终将结果直接输出到HDFS中可以参考这:
https://www.jianshu.com/p/ca165beb305b转载地址:http://varg.baihongyu.com/
你可能感兴趣的文章
Mac OS 12.0.1 如何安装柯美287打印机驱动,刷卡打印
查看>>
MangoDB4.0版本的安装与配置
查看>>
Manjaro 24.1 “Xahea” 发布!具有 KDE Plasma 6.1.5、GNOME 46 和最新的内核增强功能
查看>>
mapping文件目录生成修改
查看>>
MapReduce程序依赖的jar包
查看>>
mariadb multi-source replication(mariadb多主复制)
查看>>
MariaDB的简单使用
查看>>
MaterialForm对tab页进行隐藏
查看>>
Member var and Static var.
查看>>
memcached高速缓存学习笔记001---memcached介绍和安装以及基本使用
查看>>
memcached高速缓存学习笔记003---利用JAVA程序操作memcached crud操作
查看>>
Memcached:Node.js 高性能缓存解决方案
查看>>
memcache、redis原理对比
查看>>
memset初始化高维数组为-1/0
查看>>
Metasploit CGI网关接口渗透测试实战
查看>>
Metasploit Web服务器渗透测试实战
查看>>
MFC模态对话框和非模态对话框
查看>>
Moment.js常见用法总结
查看>>
MongoDB出现Error parsing command line: unrecognised option ‘--fork‘ 的解决方法
查看>>
mxGraph改变图形大小重置overlay位置
查看>>